Tag: tutorial
Have your say - async support in Apache Libcloud
One of the big requests whilst we were replacing httplib with the requests package in 2.0 was why didn’t
we use a HTTP library that supports asynchronous API calls.
The intention for 2.0 and replacing the HTTP backend classes was to improve the usability of the project, by making SSL certificates easier to manage, improving the maintainability of our source code by using an active 3rd party package and also improving performance and stability.
Apache Libcloud already has documentation on threaded libraries like gevent and callback-based libraries like Twisted, see using libcloud in multithreaded environments for examples.
PEP 492, implemented in Python 3.5 provides a new coroutine protocol using methods,
__await__ for classes, a coroutine method wrapper, or a method that returns a coroutine object.
Also async iterators and context managers
have been introduced.
We would like to take advantage of the new language features by offering APIs in Apache Libcloud without breaking backward compatibility and compatibility for users of <Python 3.5.
Use cases for this would be:
- Being able to fetch
NodeorStorageObjects from multiple geographies or drivers simultaneously. - Being able to quickly upload or download storage objects by parallelizing operations on the
StorageDriver. - Being able to call a long-running API method (e.g. generate report), whilst running other code.
Design 1 - async context managers PR 1016
This design would allow drivers to operate in 2 modes, the first is for synchronous method calls, they return list or object
data as per usual. The second mode, API methods like NodeDriver.list_nodes would return a coroutine object
and could be awaited or gathered using an event loop.
import asyncio
from integration.driver.test import TestNodeDriver
from libcloud.async_util import AsyncSession
driver = TestNodeDriver('apache', 'libcloud')
async def run():
# regular API call
nodes = driver.list_nodes()
async with AsyncSession(driver) as async_instance:
nodes = await async_instance.list_nodes()
assert len(nodes) == 2
loop = asyncio.get_event_loop()
loop.run_until_complete(run())
loop.close()
Design 2 - Additional methods in each driver for coroutines PR 1027
This is the second design concept for async support in Libcloud.
The concept here is to have Asynchronous Mixins, LibcloudConnection uses requests and LibcloudAsyncConnection uses aiohttp for async transport see
The LibcloudAsyncConnection is an implementation detail of AsyncConnection, which is the API for the drivers to consume see
The drivers then use this mixin for their custom connection classes, e.g.
class GoogleStorageConnection(ConnectionUserAndKey, AsyncConnection):
...
They then inherit from libcloud.storage.base.StorageAsyncDriver, which uses a new set of base methods, e.g. iterate_containers_async and can be implemented like this:
async def iterate_containers_async(self):
response = await self.connection.request_async('/')
if response.status == httplib.OK:
containers = self._to_containers(obj=response.object,
xpath='Buckets/Bucket')
return containers
raise LibcloudError('Unexpected status code: %s' % (response.status),
driver=self)
Now the consumer can more or less do this:
from libcloud.storage.providers import get_driver
from libcloud.storage.types import Provider
import asyncio
GoogleStorageDriver = get_driver(Provider.GOOGLE_STORAGE)
driver = GoogleStorageDriver(key=KEY, secret=SECRET)
def do_stuff_with_object(obj):
print(obj)
async def run():
tasks = []
async for container in driver.iterate_containers_async():
async for obj in driver.iterate_container_objects_async(container):
tasks.append(asyncio.ensure_future(do_stuff_with_object(obj)))
await asyncio.gather(*tasks)
loop = asyncio.get_event_loop()
loop.run_until_complete(run())
loop.close()
Design 3 - Initializer with “async” mode
This option is similar to 2, except that if a driver is instantiated with “async=True”,
then all driver class methods would return coroutine objects. Internally, it would
patch the Connection class with the AsyncConnection class.
The downside of this is that all method calls to a driver would need to be awaited or used by an event loop.
from libcloud.storage.providers import get_driver
from libcloud.storage.types import Provider
import asyncio
GoogleStorageDriver = get_driver(Provider.GOOGLE_STORAGE)
driver = GoogleStorageDriver(key=KEY, secret=SECRET, async=True)
def do_stuff_with_object(obj):
print(obj)
async def run():
tasks = []
async for container in driver.iterate_containers():
async for obj in driver.iterate_container_objects(container):
tasks.append(asyncio.ensure_future(do_stuff_with_object(obj)))
await asyncio.gather(*tasks)
loop = asyncio.get_event_loop()
loop.run_until_complete(run())
loop.close()
Give us feedback
Got a better idea? Have an API or design, the question we’re asking is “if you wanted to use Libcloud for an async application, what would the code look like?” This helps us design the API and the implementation details can follow.
Feel free to comment on the mailing list or on the pull requests, or raise your own pull-request with an API design.
Experimental support for the requests package
Background
I’ve just pushed a branch of the latest version of libcloud using the popular requests package by Kenneth Reitz instead of our home-rolled HTTP client library.
This article is for both users and developers of libcloud. If you want to give feedback, please join the developer mailing list.
Why?
- requests is the defacto standard - it would be in the standard library but agreed against to allow it to develop faster https://github.com/kennethreitz/requests/issues/2424
- it works with python 2.6->3.5
- Our SSL experience has a lot to be desired for Windows users, having to download the CA cert package and setting environment variables just to get SSL working
- Developers can use requests_mock for deeper integration testing
- less code to maintain
- the role of libcloud is for cloud abstraction, we provide no value in writing and maintaining our own HTTP client library
Benefits of requests
There are a number of benefits to having a requests package
- The client library code is smaller, leaner and simpler.
- Requests has built in decompression support, we no longer need to support this
- Requests has built in RAW download, upload support, helping with our storage drivers
Implications of the change
- There are no longer 2 classes (
LibcloudHTTPSConnectionandLibcloudHTTPConnection) to be provided to each driver, they are now 1 class -LibcloudConnection. You probably won’t notice this because it is a property of theConnectionclass, but if you are developing or extending functionality then it is implicated. - Unit tests will look slightly different (see below)
- This change broke 4200 unit tests (out of 6340)! I’ve since fixed them all since they were coupled to the original implementation, but now I don’t know if all of tests are valid.
Testing with requests
Unit tests that were written like this:
class DigitalOceanTests(LibcloudTestCase):
def setUp(self):
DigitalOceanBaseDriver.connectionCls.conn_classes = \
(None, DigitalOceanMockHttp)
DigitalOceanMockHttp.type = None
self.driver = DigitalOceanBaseDriver(*DIGITALOCEAN_v1_PARAMS)
Because of the change have been modified to (I updated all of them - so this is just for future reference)
class DigitalOceanTests(LibcloudTestCase):
def setUp(self):
DigitalOceanBaseDriver.connectionCls.conn_class = DigitalOceanMockHttp
DigitalOceanMockHttp.type = None
self.driver = DigitalOceanBaseDriver(*DIGITALOCEAN_v1_PARAMS)
Check it out!
The package is on my personal apache site, you can download it and install it in a virtualenv for testing.
pip install -e http://people.apache.org/~anthonyshaw/libcloud/1.0.0-rc2-requests/apache-libcloud-1.0.0-rc2-requests.zip@feature#egg=apache-libcloud
The hashes are my apache space
Have a look at the PR and the change set for a list of changes
What might break?
What I’m really looking for is for users of Libcloud to take 15 minutes, an existing (working) libcloud script, install this package in a virtualenv and just validate that there are no regression bugs with this change.
I’m particularly sceptical about the storage drivers.
Once we have enough community feedback, we will propose a vote to merge this into trunk for future release.
Credit
Credit to dz0ny on IRC for contributing some of the requests patch.
Using the container abstraction API in 1.0.0-pre1
Background
Containers are the talk of the town, you can’t escape an event or meetup without someone talking about containers. The lessons we learnt with compute abstraction are applying widely with containers in 2016. APIs are not consistent between clouds, designs are not standardised and yet, users are trying to consume multiple services.
We introduced Container-as-a-Service support in 1.0.0-pre1, a community pre-release with the intention of sparking feedback from the open-source community about the design and the implementation of 4 example drivers :
- Docker
- Joyent Triton
- Amazon EC2 Container Service
- Google Kubernetes
In this tutorial we’re going to explore how to do this:
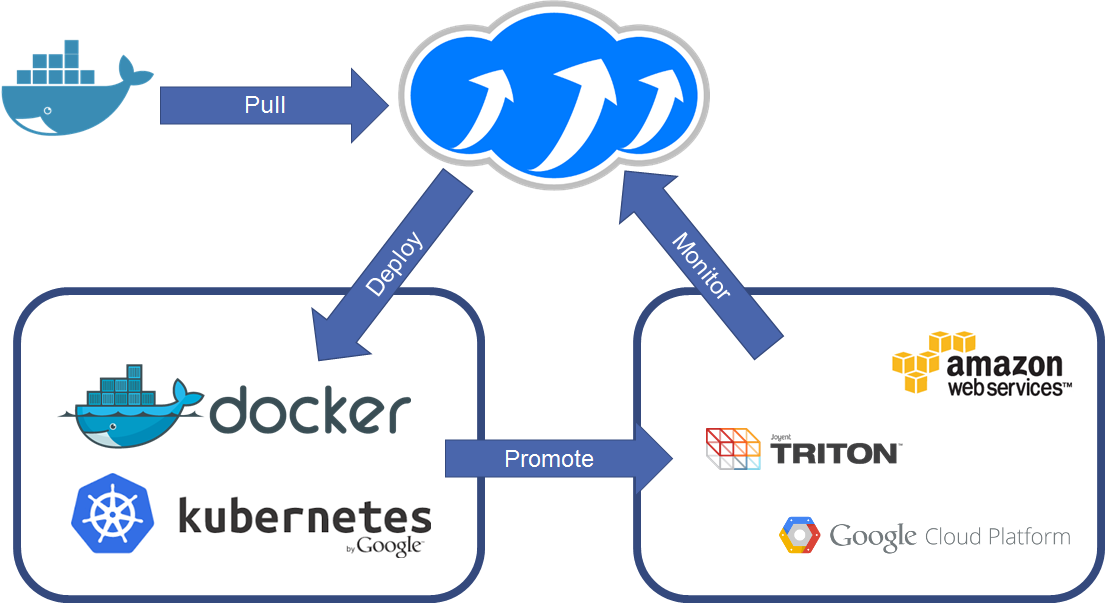
Deploying containers across platforms.
Pulling images from the Docker hub, deploying to Docker, Kubernetes and Amazon ECS then auditing them with a single query.
Getting Started with 1.0.0-pre1
First off, let’s install the new packages, you probably want to do this within a virtualenv if you’re using Apache Libcloud for other projects.
So run these commands at a Linux Shell to create a virtualenv called ‘containers’ and install the pre-release packages into that environment.
virtualenv containers
cd containers
source bin/activate
pip install apache-libcloud==1.0.0-pre1
Now you can start using this package with a test script, let’s create one called containers.py
touch containers.py
Using your favourite text editor, update that file to import the 1.0.0-pre1 libraries and the factory methods for instantiating containers.
from libcloud.container.providers import get_driver
from libcloud.container.types import Provider
get_driver is a factory method as with all libcloud APIs, you call this method with the Provider that you want to instantiate. Our options are:
Provider.DOCKER- Standalone Docker APIProvider.KUBERNETES- Kubernetes Cluster endpointProvider.JOYENT- Joyent Triton Public APIProvider.ECS- Amazon EC2 Container Service
Calling get_driver will return a reference to the driver class that you requested. You can then instantiate that class into an object using the
contructor. This is always a set of parameters for setting the host or region, the authentication and any other options.
driver = get_driver(Provider.DOCKER)
Now we can call our driver and get an instance of it called docker_driver and use that to deploy a container. For Docker you need the pem files on the server,
the host (IP or FQDN) and the port.
docker_driver = driver(host='https://198.61.239.128', port=4243,
key_file='key.pem', cert_file='cert.pem')
Docker requires that images are available in the image database before they can be deployed as containers. With Kubernetes and Amazon ECS this step is not required as when you deploy a container it carries out that download for you.
image = driver.install_image('tomcat:8.0')
Now that Docker has the version 8.0 image of Apache Tomcat, you can deploy this as a container called my_tomcat_container. Tomcat runs on TCP/8080 by default so we
want to bind that port for our container using an optional parameter port_bindings
bindings = { "22/tcp": [{ "HostPort": "11022" }] }
container = driver.deploy_container('my_tomcat_container', image, port_bindings=bindings)
This will have deployed the container and started it up for you, you can disable the automatic startup by using start=False as a keyword argument. You can now call upon this container and
run methods, restart, start, stop and destroy.
For example, to blow away that test container:
container.destroy()
Crossing the streams; calling Kubernetes and Amazon EC2 Container Service
With Docker we saw that we needed to “pull” the image before we deployed it. Kubernetes and Amazon ECS don’t have that requirement, but as a safeguard you can query the Docker Hub API using a utility class provided
from libcloud.container.utils.docker import HubClient
hub = HubClient()
image = hub.get_image('tomcat', '8.0')
Now image can be used to deploy to any driver instance that you create. Let’s try that against Kubernetes and ECS.
Amazon ECS
Before you run this example, you will need an API key and the permissions for that key to have the AmazonEC2ContainerServiceFullAccess role. ap-southeast-2 is my nearest region, but you can
swap this out for any of the Amazon public regions that have the ECS service available.
e_cls = get_driver(Provider.ECS)
ecs = e_cls(access_id='SDHFISJDIFJSIDFJ',
secret='THIS_IS)+_MY_SECRET_KEY+I6TVkv68o4H',
region='ap-southeast-2')
ECS and Kubernetes both support some form of grouping or clustering for your containers. This is available as create_cluster, list_cluster.
cluster = ecs.create_cluster('default')
container = ecs.deploy_container(
cluster=cluster,
name='hello-world',
image=image,
start=False,
ex_container_port=8080, ex_host_port=8080)
This will have deployed a task definition in Amazon ECS with a single container inside, with a cluster called ‘main’ and deployed the tomcat:8.0 image from the Docker hub to that region.
Check out the ECS Documentation for more details.
Kubernetes
Kubernetes authentication is currently only implemented for None (off) and Basic HTTP authentication. Let’s use the basic HTTP authentication method to connect.
k_cls = get_driver(Provider.KUBERNETES)
kubernetes = k_cls(key='my_username',
secret='THIS_IS)+_MY_SECRET_KEY+I6TVkv68o4H',
host='126.32.21.4')
cluster2 = kubernetes.create_cluster('default')
container2 = kubernetes.deploy_container(
cluster=cluster,
name='hello-world',
image=image,
start=False)
Wrapping it up
Now, let’s wrap that all up by doing a list comprehension across the 3 drivers to get a list of all containers and print their ID’s and Names. Then delete them.
containers = [conn.list_containers() for conn in [docker, ecs, kubernetes]]
for container in containers:
print("%s : %s" % (container.id, container.name))
container.destroy()
About the Author
Anthony Shaw is on the PMC for Apache Libcloud, you can follow Anthony on Twitter at @anthonypjshaw.